
Die Robotik-Branche hütet ein offenes Geheimnis, das so manchem CEO den Schlaf raubt: Robotern beizubringen, auch nur ansatzweise nützlich zu sein, ist eine schmerzhaft langwierige und astronomisch teure Angelegenheit. Jahrelang galt die gängige Lehrmeinung, Intelligenz mit Vision-Language-Action-Modellen (VLAs) quasi mit der Brechstange zu erzwingen – ein Ansatz, der zehntausende Stunden menschlicher Arbeit verschlingt, in denen Menschen Roboter minutiös durch jede erdenkliche Aufgabe fernsteuern. Das ist ein Datenengpass von epischem Ausmaß, der selbst Sisyphos zum Fluchen bringen würde.
Doch jetzt wagt das Robotikunternehmen 1X einen Vorschlag, der schon fast ketzerisch anmutet. Ihr neuer Ansatz für den Humanoiden NEO ist trügerisch einfach: Schluss mit dem mühsamen Pauken! Lasst den Roboter einfach lernen, indem er die riesige, chaotische und unendlich lehrreiche Bibliothek menschlichen Verhaltens studiert, die wir liebevoll „das Internet“ nennen. Das ist nicht nur ein Upgrade; es ist ein fundamentaler Paradigmenwechsel in der Art und Weise, wie ein Roboter Fähigkeiten erwerben kann – quasi ein Quantensprung auf Speed.
Das datenhungrige Biest von gestern
Um den Sprung, den 1X hier macht, wirklich zu würdigen, muss man den Status quo verstehen. Die meisten modernen Grundmodelle für die Robotik, von Figure’s Helix bis zu Nvidia’s GR00T, sind VLAs. Diese Modelle sind zwar mächtig, aber sie haben einen unstillbaren Hunger nach hochwertigen, roboterspezifischen Demonstrationsdaten. Das bedeutet: Menschen werden dafür bezahlt, Roboter tausende von Stunden fernzusteuern, um Beispiele zu sammeln – etwa, wie man eine Tasse aufhebt oder ein Handtuch faltet. Ein Traumjob für alle, die schon immer mal Roboter-Pantomime betreiben wollten.
Dieser Ansatz ist ein gewaltiges Hindernis auf dem Weg zu wirklich universell einsetzbaren Robotern. Er ist teuer, skaliert miserabel, und die resultierenden Modelle können zerbrechlich sein; sie versagen kläglich, wenn sie mit einem Objekt oder einer Umgebung konfrontiert werden, die sie noch nie zuvor gesehen haben. Es ist, als würde man versuchen, einem Kind das Kochen beizubringen, indem man es nur in der eigenen Küche zusehen lässt, anstatt es jede Kochsendung, die jemals produziert wurde, „binge-watchen“ zu lassen. Man stelle sich vor, Gordon Ramsay würde nur in einer Küche kochen dürfen!
Träumereien vom… Hausputz
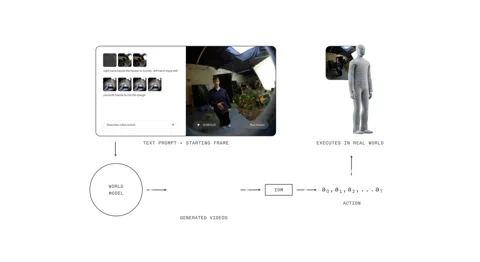
Das 1X World Model (1XWM) wirft dieses alte Drehbuch kurzerhand über Bord. Anstatt Sprache direkt auf Aktionen abzubilden, nutzt es textkonditionierte Videogenerierung, um herauszufinden, was zu tun ist. Es ist ein zweiteiliges Gehirn, das dem Roboter im Grunde erlaubt, die Zukunft zu imaginieren, bevor er überhaupt einen Finger krümmt.
Zuerst wäre da das World Model (WM), ein generatives Videomodell mit 14 Milliarden Parametern, das als die Fantasie des Systems fungiert. Man gibt NEO einen Text-Prompt – „Verpacke diese Orange in die Brotdose“ – und das WM, das die aktuelle Szene betrachtet, ersinnt ein kurzes, plausibles Video, wie die Aufgabe erledigt wird. Quasi ein mentaler Probelauf, bevor es ernst wird.
Danach analysiert das Inverse Dynamics Model (IDM), der Pragmatiker in der Maschine, diesen Traum. Es übersetzt die generierten Pixel in eine konkrete Abfolge von Motorbefehlen und schlägt so die Brücke zwischen einem visuellen Was und einem physischen Wie. Dieser Prozess wird durch eine mehrstufige Trainingsstrategie verankert: Das Modell beginnt mit Videos im Web-Maßstab, wird in der Mittelphase mit 900 Stunden egozentrischer menschlicher Videos trainiert, um eine Ich-Perspektive zu erhalten, und schließlich mit mageren 70 Stunden NEO-spezifischer Daten feinabgestimmt, um sich an den eigenen Körper anzupassen. Ein Trainingsmarathon, der mit einem Sprint endet.

Ein genialer Kniff in ihrer Trainings-Pipeline ist das „Caption Upsampling“. Da viele Video-Datensätze eher knappe Beschreibungen aufweisen, nutzt 1X ein VLM, um reichhaltigere, detailliertere Bildunterschriften zu generieren. Das sorgt für eine klarere Konditionierung und verbessert die Fähigkeit des Modells, komplexen Anweisungen zu folgen – eine Technik, die bereits bei Bildmodellen wie OpenAI’s DALL-E 3 ähnliche Vorteile gezeigt hat. Man könnte sagen: Sie füttern die KI nicht nur mit Daten, sondern auch mit Poesie.
Der humanoide Vorteil
Dieser gesamte „Video-First“-Ansatz hängt an einem entscheidenden – und vielleicht offensichtlichen – Stück Hardware: Der Roboter ist wie ein Mensch geformt. Das 1XWM, trainiert mit unzähligen Stunden menschlicher Interaktion mit der Welt, hat ein tiefes, implizites Verständnis für physikalische Grundsätze entwickelt – Schwerkraft, Impuls, Reibung, Objektaufforderungen (Affordanzen) –, die sich direkt übertragen lassen, weil NEOs Körper sich auf eine fundamental menschenähnliche Weise bewegt. Es ist, als hätte man der KI einen menschlichen Körper als Cheat-Code gegeben.
Wie 1X es ausdrückt, ist die Hardware ein „Bürger erster Klasse im AI-Stack“. Die kinematischen und dynamischen Ähnlichkeiten zwischen NEO und einem Menschen bedeuten, dass die gelernten Grundsätze des Modells im Allgemeinen gültig bleiben. Was das Modell visualisieren kann, kann NEO meistens auch tatsächlich ausführen. Diese enge Integration von Hardware und Software schließt die oft tückische Kluft zwischen Simulation und Realität. Ein echtes „Dreamteam“ aus Bits und Bolzen.
Von der Theorie zur Realität (mit ein paar Stolpersteinen)
Die Ergebnisse sind überzeugend. Das 1XWM ermöglicht es NEO, Aufgaben und Objekte zu verallgemeinern, für die es keinerlei direkte Trainingsdaten gab. Das Werbevideo zeigt, wie es ein Hemd bügelt, eine Pflanze gießt und sogar eine Toilettenspülung betätigt – eine Aufgabe, für die es keinerlei Vorerfahrung hatte. Das deutet darauf hin, dass das Wissen für zweihändige Koordination und komplexe Objektinteraktion erfolgreich aus den menschlichen Videodaten übertragen wird. Wer hätte gedacht, dass das Geheimnis der Robotik in einem sauberen WC liegt?
Aber das ist keine Zauberei. Das System hat seine Grenzen. Generierte Ausführungen können „übertrieben optimistisch“ sein, was den Erfolg angeht, und sein monokulares Vortraining kann zu einer schwachen 3D-Verankerung führen. Das wiederum kann dazu führen, dass der echte Roboter ein Ziel unter- oder überschießt, selbst wenn das generierte Video perfekt aussieht. Erfolgsquoten bei geschickten Aufgaben wie Müsli eingießen oder ein Smiley zeichnen bleiben weiterhin eine Herausforderung. Manchmal ist die Realität eben doch hartnäckiger als die KI-Fantasie.
Dennoch hat 1X einen vielversprechenden Weg gefunden, die Leistung zu steigern: „Test-Time Compute“. Bei einer Aufgabe wie dem „Papiertuch ziehen“ sprang die Erfolgsquote von 30 % bei einer einzigen Videogenerierung auf 45 %, als das System acht verschiedene mögliche Zukünfte generieren und die beste auswählen durfte. Während diese Auswahl derzeit noch manuell erfolgt, deutet dies auf eine Zukunft hin, in der ein VLM-Evaluator den Prozess automatisieren und die Zuverlässigkeit erheblich verbessern könnte. Bald wählt die KI selbst ihren besten Traum aus.
Das Schwungrad des Selbstlernens
Das 1XWM ist mehr als nur ein inkrementelles Update; es ist ein potenzieller Paradigmenwechsel, der den Datenengpass weit aufreißen könnte. Es schafft ein Schwungrad zur Selbstverbesserung. Indem NEO eine breite Palette von Aufgaben mit einer Erfolgsquote ungleich null versuchen kann, kann es nun seine eigenen Daten generieren. Jede Aktion, ob Erfolg oder Misserfolg, wird zu einem neuen Trainingsbeispiel, das in das Modell zurückgespeist werden kann, um seine Strategie zu verfeinern. Der Roboter beginnt, sich selbst zu unterrichten – ein wahrer Autodidakt auf zwei Beinen.
Natürlich bleiben große Hürden bestehen. Das WM benötigt derzeit 11 Sekunden, um einen 5-sekündigen Plan zu generieren, und eine weitere Sekunde für das IDM, um die Aktionen zu extrahieren. Diese Latenz ist eine Ewigkeit in einer dynamischen, realen Umgebung und ein „No-Go“ für reaktive Aufgaben oder filigrane, kontaktintensive Manipulationen. Man stelle sich vor, man müsste 11 Sekunden warten, um einen Kaffee zu kochen!
Dennoch: Indem 1X das Datenproblem frontal angeht, hat das Unternehmen möglicherweise gerade die Tür zu einer Zukunft aufgestoßen, in der Roboter nicht mehr aus unseren mühsamen Anweisungen lernen, sondern aus unserer kollektiven, aufgezeichneten Erfahrung. Diese Zukunft nimmt Fahrt auf, ein Internetvideo nach dem anderen – und wir sind gespannt, welche TikTok-Tänze NEO als Nächstes lernt.
