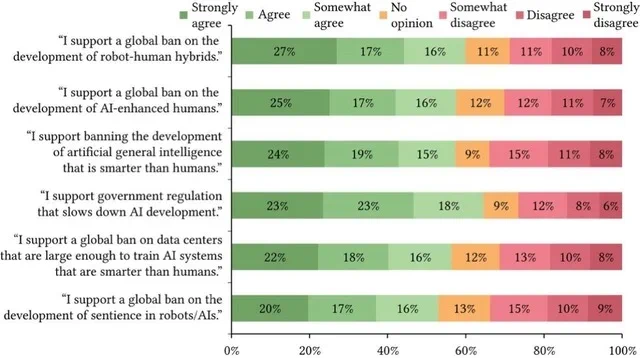
Wer glaubt, dass die größte Story in der Robotik derzeit ein zweibeiniger Roboter ist, der nicht umfällt, schaut in die falsche Richtung. Etwas weitaus Epochaleres braut sich zusammen – und zwar nicht in den Hardware-Laboren, sondern in den Datensätzen. Eine Revolution findet statt, versteckt vor aller Augen auf Plattformen wie Hugging Face, angetrieben durch eine exponentielle Explosion von Open-Source-Daten.
Während Large Language Models (LLMs) sich seit Jahren am offenen Internet sattessen, mussten Roboter bisher hungern. Sie lernen nicht aus Textwüsten; sie lernen aus der unordentlichen, chaotischen Realität der physischen Welt – aus Video-Feeds, Gelenkbewegungen, Sensorströmen und, was am wichtigsten ist, aus Fehlern. Historisch gesehen waren diese kostbaren Daten die Kronjuwelen der Robotikunternehmen, weggesperrt in proprietären Tresoren. Diese Ära ist nun endgültig vorbei. Allein im letzten Jahr ist die Zahl der Robotik-Datasets auf Hugging Face von 1.145 auf fast 27.000 hochgeschossen. Das ist ein Anstieg von 2.400 %. Damit katapultierte sich die Kategorie innerhalb von nur drei Jahren von Platz 44 auf Platz 1 und ließ sogar die Textgenerierung, die bei bescheidenen 5.000 Datensätzen stagniert, weit hinter sich.
Die Daten-Sintflut
Das hier ist keine bloße Sammlung von Hobbyprojekten. Die Grafik, bereitgestellt vom Tech-Analysten Pierre-Alexandre Balland, illustriert eine kambrische Explosion des geteilten Robotik-Wissens. Die Daten sind so gefiltert, dass nur Datensätze mit mehr als 200 Downloads berücksichtigt werden – ein klares Indiz dafür, dass dieses riesige Repository aktiv für Experimente und das Training von Modellen genutzt wird.

Dieser rasanten Entwicklung liegt ein “Perfect Storm” zugrunde: günstigere Speicherpreise, bessere Tools und das Open-Source-Ethos der KI-Welt, das nun endlich auf die Hardware überschwappt. Plattformen wie Hugging Face haben die Hürden für das Teilen von Daten massiv gesenkt und ein kollaboratives Ökosystem ermöglicht, das vor fünf Jahren noch undenkbar gewesen wäre. Initiativen wie LeRobot zielen darauf ab, Formate und Werkzeuge zu standardisieren, damit jeder einfacher beitragen und von den gemeinsamen Daten profitieren kann.
Die neuen Daten-Barone
Wer also öffnet hier die Schleusen? Während man NVIDIA vor allem für seine GPUs kennt, entwickelt sich das Unternehmen rasend schnell zu einer dominierenden Macht im Bereich der Robotik-Daten. Allein im Jahr 2025 wurden die Open-Source-Datasets von NVIDIA über 9 Millionen Mal heruntergeladen. Ihre Datensätze für das Post-Training des Isaac GR00T Generalist-Robotermodells sind mit 7,9 Millionen Downloads im vergangenen Jahr die meistgeladenen auf der gesamten Plattform. Das ist keine reine Wohltätigkeit, sondern ein strategischer Geniestreich: NVIDIA baut die fundamentale Infrastruktur für das gesamte Feld auf und stellt sicher, dass ihre Hardware das Zentrum dieses Ökosystems bleibt.
Doch sie sind nicht allein. Die Rangliste der Daten-Pioniere liest sich wie das Who-is-Who der globalen KI-Elite:
- Das Shanghai AI Lab folgt dicht auf den Fersen mit beeindruckenden 7,6 Millionen Downloads.
- Hugging Face selbst kommt durch eigene Initiativen auf 1,4 Millionen.
- Akademische Zentren wie das Stanford Vision and Learning Lab (SVL) steuerten Datensätze mit über 710.000 Downloads bei.
- Weitere Schwergewichte sind AgiBot, Yaak AI, AllenAI und sogar Hardware-Hersteller wie Unitree Robotics.

Warum das die wahre Revolution ist
Über Jahrzehnte hinweg wurde der Fortschritt in der Robotik durch eine simple, bittere Realität ausgebremst: Jedes Labor musste das Rad neu erfinden. Um einem Roboter beizubringen, eine Tasse aufzuheben, brauchte es ein Team von promovierten Experten, einen maßgeschneiderten Roboter und tausende Stunden mühsamer Datensammlung. Das Ergebnis? Hochspezialisierte, fragile Maschinen, die in dem Moment versagten, in dem man die Tasse zwei Zentimeter nach links schob.
Das neue Open-Data-Paradigma sprengt diesen Flaschenhals:
- Senkung der Eintrittshürden: Ein Startup mit einem neuartigen Lernalgorithmus benötigt kein millionenschweres Hardware-Setup mehr, um loszulegen. Sie können Terabytes an Echtweltdaten von dutzenden verschiedenen Robotern und Umgebungen herunterladen, um ihre Modelle zu trainieren und zu validieren.
- Beschleunigtes Benchmarking: Durch gemeinsam genutzte Datensätze kann die gesamte Branche verschiedene Ansätze nun auf Augenhöhe vergleichen. Das trennt die Spreu vom Weizen und belohnt Algorithmen, die auch unter unvorhersehbaren Bedingungen funktionieren.
- Der Flywheel-Effekt: Mehr qualitativ hochwertige Daten führen zu besseren Foundation Models. Bessere Modelle ermöglichen komplexere Anwendungen, die wiederum mehr – und interessantere – Daten generieren. Dieser positive Kreislauf ist der Motor, der die Robotik endlich aus dem Labor in unseren Alltag bringen wird.
Die Zukunft der Robotik wird nicht von dem Unternehmen definiert, das die glänzendste Hardware baut, sondern von dem Ökosystem mit den reichsten und vielfältigsten Daten. Während tanzende Humanoide tolle Videos abgeben, ist das stille, exponentielle Wachstum geteilter Datensätze das wahre Fundament, das gerade gegossen wird. Die Open-Source-Revolution, die die Softwarewelt transformiert hat, ist endlich in der physischen Welt angekommen – ein Datensatz nach dem anderen.